[BigData] 데이터 시각화
key word : 데이터 시각화, 데이터 집계, 데이터 집계 고속화
데이터를 탐색하기 위해서 필요한 정보를 시각화하는 작업이 필요하다. 이 과정에서 데이터 집계가 이뤄지며, 집계된 결과를 따로 저장하는 등 데이터 마트를 구성하기도 한다. 이러한 일련의 과정에 대해 알아보고자 한다.
데이터 시각화 과정
데이터를 보여주는 테이블은 크게 트랜잭션 테이블과 크로스 테이블로 나눌 수 있다. 트랜잭션 테이블은 데이터베이스에 쿼리를 날려 조회한 결과와 같이 여러 행에 필요한 정보가 담겨있는 테이블이다. 이와는 달리 열과 행의 조합으로 데이터를 표시하는 테이블을 크로스 테이블이라고 한다. 인간이 보기에는 크로스 테이블이 더 데이터를 탐색하는데 알맞다고 할 수 있다. 이렇듯 데이터를 탐색하기 좋은 형태로 나타내는 것이 데이터 시각화이며, 트랜잭션 테이블을 크로스 테이블로 변환하는 ‘크로스 집계’는 이러한 방법 중 한 가지라고 할 수 있다.
크로스 테이블
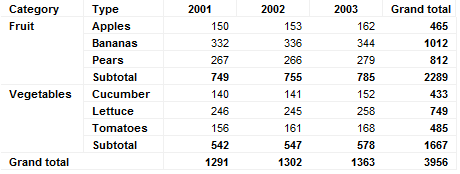
트랜잭션 테이블
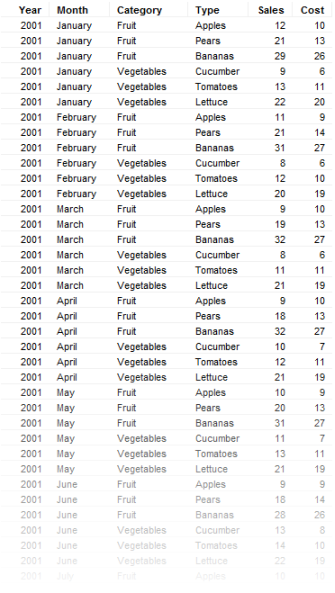
출처 : https://docs.tibco.com/pub/spotfire/6.5.2/doc/html/cross/cross_what_is_a_cross_table.htm
크로스 집계를 할 수 있는 가장 간단한 방법으로는 엑셀이나 구글 스프레드 시트와 같은 스프레드 시트의 피벗 테이블 기능을 이용하는 것이 있다. 혹은 Tableau와 같은 BI 도구, Pandas와 같은 스크립트를 이용해서도 크로스 집계를 할 수 있다.
위에서 언급한 크로스 집계는 결국 변환할 모든 데이터가 메모리 상에 올라가 있어야만한다는 점에서 빅데이터에는 사용하지 못한다. 대량의 데이터를 집계할 때는 SQL로 집계 함수를 이용해 처리할 수 있다. 다만 데이터베이스에서 바로 크로스 테이블을 구성하거나 시각화하는 것은 어려운 일이므로 필요한 데이터를 집계한 후 데이터의 양을 줄여 시각화를 위한 툴을 추후에 사용하는 방식을 주로 이용한다.
한 번 처리한 데이터를 저장하는 곳을 데이터 마트라고 하며, 데이터 시각화의 과정을 개괄적으로 보자면 데이터 레이크 -> 데이터 마트 -> 시각화로 정리할 수 있다.
예를 들어보자면 데이터베이스에서 필요한 데이터를 집계해 데이터 마트에 저장하고, 그 데이터로 크로스 테이블이나 대시보드 등을 만든다고 생각하면 된다.
데이터 집계의 고속화
빠른 데이터 집계를 위한 가장 좋은 방법은 데이터를 메모리에 모두 올려놓고 단번에 집계 처리를 하는 것이다. 우리가 흔히 사용하는 RDB를 이용하면 빠르게 처리할 수 있어 적은 양의 데이터를 처리할 경우 RDB가 데이터 마트로 사용되기도 한다. 또한 여러 사람이 데이터베이스를 동시에 이용해도 안정적이고 빠르게 작업을 처리할 수 있다는 장점도 있다. 하지만 데이터가 메모리에 한 번에 올라갈 수 없다면 디바이스 I/O가 발생하므로 성능이 저하된다.
메모리에 한 번에 올리지 못할 대량의 데이터를 빠르게 처리하고자 할 때에는 데이터를 분산, 압축해 저장하는 방식을 이용해야 한다. 특히 열 단위로 데이터 압축이 되는 열 지향 데이터베이스를 이용하면 데이터를 압축해 디스크 I/O를 줄일 수 있다. 더 나아가 MPP(massive parallel processing) 아키텍처를 이용하면 분산 저장된 데이터를 병렬 처리해 집계할 수 있다. 집계해야할 레코드들을 여러 그룹으로 쪼개어 각자 계산하고, 그 결과로 또 다시 집계를 하는 방식을 통해 빠르게 집계 처리를 할 수 있다.
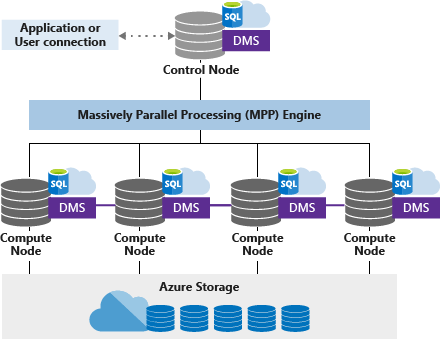
출처 : https://medium.com/@putrasulung2108/mpp-architecture-6bfb11b27a6a
이러한 병렬 처리는 일반적인 행 지향의 RDB에서는 처리할 수 없고, 열 지향 데이터베이스를 이용해야 한다. 데이터를 열 단위로 저장하고, 압축할 수 있기 때문에 집계에 필요한 열만 로드해 병렬로 처리할 수 있다는 장점이 있다.
참고
빅데이터를 지탱하는 기술, 니시다 케이스케, 제이펍, 2021(전자책)