[BigData] 분산처리
key word : 분산처리, 분산처리 프레임워크, Hadoop, Spark
분산처리란?
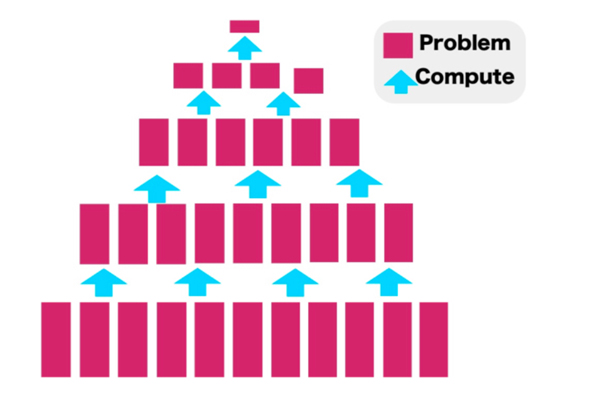
분산처리란 말 그대로 하나의 작업을 여러 곳에 나누어 처리하는 것을 말한다. 알고리즘의 분할 정복 기법을 생각하면 이해가 쉽다. 복잡한 문제를 여러 개의 단순한 문제로 만들어 하나씩 해결해 최종적인 답을 찾는 방법이다.
출처 : https://dataonair.or.kr/db-tech-reference/d-lounge/technical-data/?mod=document&uid=235894
대규모의 데이터를 나누어 처리함으로써 처리하는데 드는 시간을 단축시킬 수 있다. 물론 코어가 매우 많은 고성능의 cpu를 이용하여 여러 프로세서를 이용한 병렬처리를 할 수도 있지만, 확장성과 유연성 그리고 비용의 관점에서 볼 때 한 대의 슈퍼컴퓨터보다 여러 대의 컴퓨터로 처리를 하는 분산 컴퓨팅이 더 낫다.
클러스터
분산 처리에는 여러 컴퓨터와 각각의 컴퓨터를 연결하는 네트워크가 필요하다. 이 구성을 클러스터라고 한다.
분산처리 프레임워크
-
Hadoop
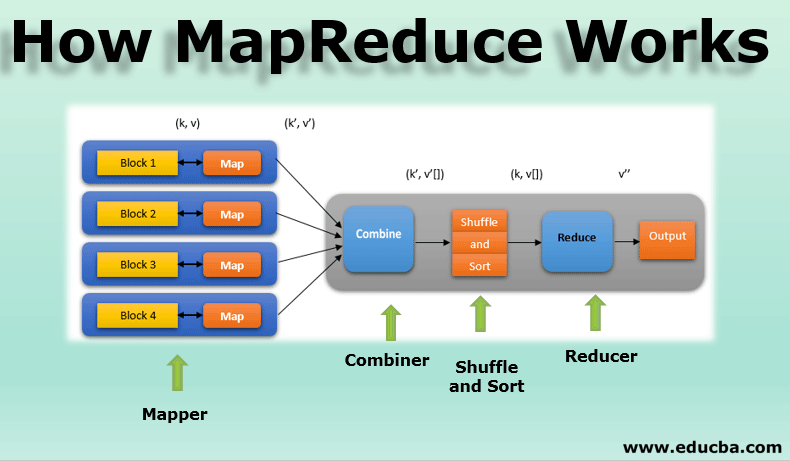
Hadoop은 클러스터를 쉽게 활용할 수 있게 해주는 프레임워크 중 하나로 단일 소프트웨어가 아닌 다수의 소프트웨어로 이루어진 집합체이다. HDFS, YARN, MapReduce를 기본 구성으로 한다. HDFS에 데이터를 저장하고, YARN을 이용해 분산 처리를 위한 리소스를 관리한다. MapReduce를 이용해 데이터를 나눠 클러스터로 보내고 그 결과를 수집할 수도 있다.
출처 : https://www.educba.com/how-mapreduce-work/
MapReduce는 데이터를 키-값의 쌍으로 읽어들여 변환하는 Map()과 그 결과를 그룹화하여 집계하는 등 데이터를 처리하는 Reduce()로 역할이 나뉜다. 이 과정에서 MapReduce는 데이터를 디스크에 두고 작업하므로 디스크 읽기/쓰기에 많은 리소스를 사용하게 되고 데이터가 작을 경우 오히려 오버헤드가 발생할 수 있다는 단점이 존재한다.
Hadoop을 이용한 분산 시스템의 구성은 기본적으로 위와 같지만 Amazon S3나 Spark 등을 이용해 다른 구성으로 만들 수 있다.
-
Spark
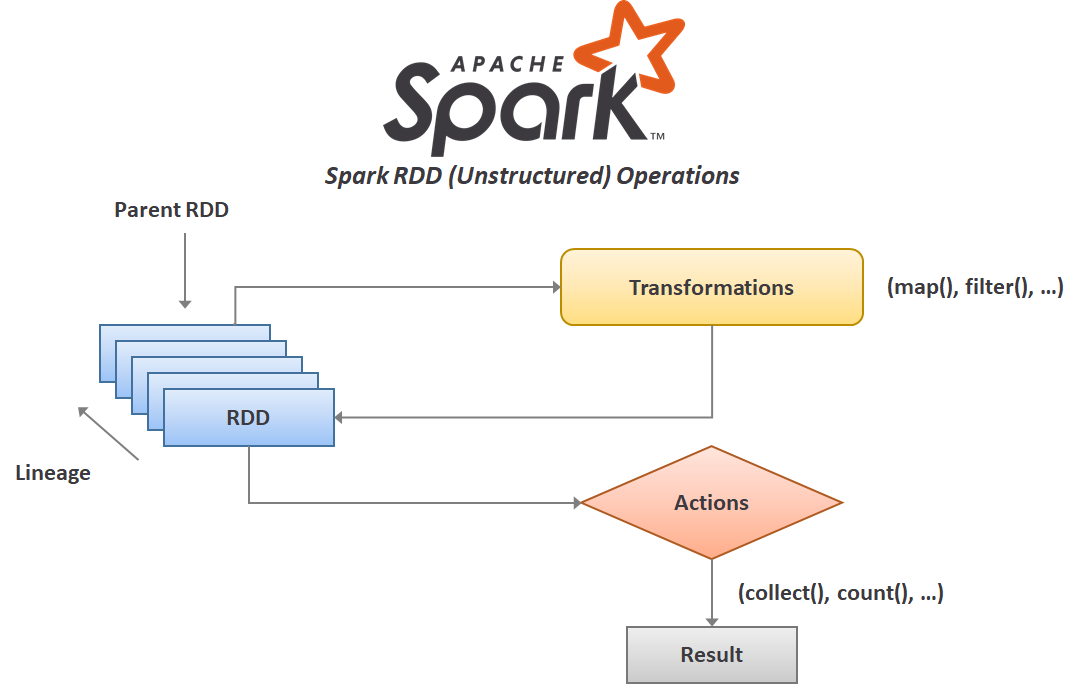
Spark 또한 MapReduce처럼 데이터를 분산 처리할 수 있는 프로젝트이다. Spark의 가장 큰 특징은 메모리를 대량으로 사용하여 고속처리가 가능하다는 점이다. 하드웨어의 발전으로 메모리의 용량이 커져 중간 결과를 디스크에 기록하지 않아도 메모리상에서 모든 처리를 할 수 있게 됐다. 어차피 고속이기때문에 중간에 오류가 생기더라도 다시 처리하면 된다는 장점이 있다.
출처 : https://medium.com/analytics-vidhya/spark-rdd-low-level-api-basics-using-pyspark-a9a322b58f6
Spark는 Hadoop에 대응하는 소프트웨어는 아니고, MapReduce를 대체할 수 있는 프로젝트이다. 즉, 위에서 언급한 것과 같이 AmazonS3, YARN과 함께 Spark를 이용한 분산 시스템을 구성할 수 있다.
Spark는 SQL 쿼리 실행이 가능한 Spark SQL과 스트림 처리를 수행할 수 있는 Spark Streaming이라는 기능이 포함되어 있어 대화형 쿼리 실행 및 실시간 스트림 처리도 가능하다는 특징을 가지고 있다.
참고
빅데이터를 지탱하는 기술, 니시다 케이스케, 제이펍, 2021(전자책)
https://dataonair.or.kr/db-tech-reference/d-lounge/technical-data/?mod=document&uid=235894